

Almost every day, we are assaulted with “studies” purporting to have found correlations, connections, links, or ties between causes and effects. In 1998 Dr. Andrew Wakefield claimed that exposure to MMR vaccine causes autism. That assertion still reverberates across Europe and the U.S., but how reliable is Wakefield’s study? What about the claim that increased carbon dioxide emissions are causing and will continue to cause global temperature to rise, wreaking havoc with ecosystems all over planet Earth? Or the claim that taking vitamin A tablets will reduce the risk of melanoma? How is someone—especially a non-scientist—supposed to know what to believe?
It is important to learn first that not all “studies” are equally credible. Many factors can influence the outcome of an investigation into the cause of some phenomenon, whether autism, global warming, or melanoma. In this essay, I will discuss those factors in the context of the methods of epidemiology and four major kinds of study: clinical trials, cohort studies, case-control studies, and ecologic studies.
Three Levels of Clinical Trial
Not all clinical trials are equally credible. Just because “a clinical trial at a major university” supports claims made for a product doesn’t mean it provides any benefits.
 Phase I Clinical Trial
Phase I Clinical Trial
The first clinical trial typically done with a proposed medication is a phase I clinical trial. This involves administration of the proposed medication to a small number of healthy people in order to ascertain whether it causes any adverse effects. It indicates nothing about its benefits.
Phase II Clinical Trial
If the drug proves to be safe, then a phase II clinical trial will be conducted as a first step toward determining its efficacy. In this trial, the proposed medication is given to a larger group of individuals who are suffering from the illness the medication is supposed to treat. However, because all participants know they are receiving the new drug, there is enormous potential for the placebo effect—the benefit to be gained from simply believing that a drug will work.
The placebo effect is real and potentially huge. A shot of saline is as effective as a shot of morphine, if one only believes! Consequently, the phase II clinical trial is insufficient to prove a product’s efficacy. Doing that requires a much more rigorous, carefully controlled trial.
Phase III Clinical Trial
The absolute best method—the “gold standard”—for ascertaining the true cause or effect of a phenomenon is the phase III clinical trial.
The phase III clinical trial has been called the most important discovery of modern medicine—more important than vaccines (which have saved millions of lives), antibiotics (which have saved millions more), and anesthesia (which has prevented unimaginable amounts of pain). Why?
Because the phase III clinical trial is the only way to know if a medication actually works.
Prior to the development of the phase III clinical trial, snake oil salesmen could pawn their impotent potions off on desperate people—leaving millions to die. Now the Food and Drug Administration (FDA) demands phase III clinical trial evidence that a medication works before it can be marketed as a medication.
Note: if the fine print on any “medication” says, “These statements have not been evaluated by the FDA,” then there is no phase III clinical trial evidence that it works as it claims. View any such claims skeptically.
Nine Conditions for Proper Phase III Clinical Trials
 Nine fundamental conditions of a proper phase III clinical trial are placebo control, randomization, sample size, reproducibility, proper statistical analysis, precluding—by proper planning of how to handle test results—bias in researchers’ reporting of test results, distinguishing low-dose from high-dose effects, and distinguishing different species’ responses to substances.
Nine fundamental conditions of a proper phase III clinical trial are placebo control, randomization, sample size, reproducibility, proper statistical analysis, precluding—by proper planning of how to handle test results—bias in researchers’ reporting of test results, distinguishing low-dose from high-dose effects, and distinguishing different species’ responses to substances.
1. Placebo Control through Double-Blind Trial
To rule out the placebo effect, a phase III clinical trial compares the use of a placebo with the use of a candidate drug. The benefit gained from taking only a placebo is subtracted from the benefit gained from taking the drug. If the result is zero, the drug works no better than a placebo.
A phase III clinical trial is—or ought to be—placebo-controlled. If a “study” lacks comparison with a placebo, be very suspicious.
To properly rule out a placebo effect, the phase III clinical trial must be conducted in a “double-blind” manner:
- First, trial participants must not know if they are receiving product or placebo.
- Second, trial technicians must not know if they are giving product or placebo, to eliminate the chance they might treat one group differently from the other.
- Third (the trial really should be called “triple blind”), trial supervisors must not know who received product or placebo, to eliminate bias when analyzing the data.
Eliminating bias is important because people who own or work for the company that created the product (usually at great cost) want it to work, which could influence their assessment of results.
Another way to reduce bias is to require an objective measure of efficacy, rather than relying on someone’s subjective assessment.
2. Randomization
The next critical component of a high-quality phase III clinical trial is randomization. Test subjects must be distributed into product and placebo groups randomly.
If only females, or only elderly participants, or only smokers are placed in the placebo group, that could affect the results enormously. Individuals in the product and placebo groups must have the same age distribution, the same ratio of genders, the same predisposition to disease, the same genetic background, etc.
The two groups must be treated in the same way, which should be made easier if trial technicians are blind to which individuals are receiving the placebo. The two groups should also have approximately equal numbers.

Furthermore, the people designing the trial need to state how randomization was achieved. Random does not mean left to chance! Chance can produce some strange results, like more females in one group than the other. Randomization means intentionally making the two groups as balanced as possible.
In recruiting people to participate in a clinical trial, it is common to exclude certain individuals from participating. The criteria used to exclude some individuals must be stated. Excluding certain people could bias the results of the trial and will limit the applicability of the trial results to the general population. It is important that clinical trial groups be representative of the groups of people who will use the product. It is not legitimate to test a drug on adults and then use it on children (although testing on children carries its own ethical issues). Another way to state this is that the study designers need to avoid sampling error.
If it is necessary to drop participants out of a clinical trial, that ought to be admitted and the reasons for attrition given, since that, too, could influence the results of the study. If several participants dropped out of the drug arm of a clinical trial because the medication made them dreadfully ill, that side effect is extremely relevant to the results of the trial.
3. Sample Size
The next requirement for a valid phase III clinical trial is whether the sample size is adequate for the effect expected. Without adequate sample size, valid statistical analysis is impossible.
It’s not hard to see that conducting a trial with a small sample of people is susceptible to all kinds of completely chance affects. For example, in a placebo group of eight people, it is possible, strictly by chance, that two will develop colon cancer, even if none in an equal-size test group receiving the actual candidate medication will. If the test is of vitamin D, then vitamin D will appear to reduce the chance of colon cancer significantly! Having larger groups of participants will reduce the odds of getting such chance results.
How large a sample is necessary? It depends on many factors, but for the typical level of statistical significance (0.05) and power (80%), in the simplest cases, if the effect is large, two groups of about 26 each will be able to reveal the difference. If the effect is moderate, each group will need to have at least 65 members. And if the effect is small (and that, of course, is a relative term), each group—control and test—will need at least 400 individuals. Bottom line: beware small studies!
In achieving the appropriate sample size, it is important to understand the difference between independent and replicate data. Independent data are separate experiments of the same type that are not linked, e.g., 65 randomly assigned people all receiving the same drug. Replicate data are linked as much as possible, e.g., the same drug given to a litter of eight rat pups. Only independent data count toward the desired sample size; replicate data do not.
Think about it—would this drug work equally well on any litter of rat pups? Not necessarily. Genetic differences between Litter A and Litter B might result in different results from the same drug given to the two litters. Each litter, despite its having multiple pups, yields only one data point.
Consider another example: a college professor teaching 25 students in an on-line as opposed to a lecture format. In this case, N (sample size) = 1, not 25. If he teaches the same material to 25 students on-line and 45 students in a face-to-face classroom setting, N = 2, not 70. No valid p-value (the probability of obtaining by chance a test statistic as extreme as that observed in the trial) can be calculated for N = 1.
4. Reproducibility
What we are striving for is true reproducibility, i.e., the experiment was repeated a large number of times, under various conditions. This gives us a more robust result, applicable to a wide variety of individuals. Only showing the results of a single “representative” experiment introduces enormous potential for bias in the selection of the “representative” experiment.
 5. Proper Statistical Analysis
5. Proper Statistical Analysis
The standard for statistical claims of cause is at least a 95% probability that the correlation is real and not due to chance. The strength of the correlation observed is called its p-value: the probability that the correlation occurs by chance instead of by actual causation. Hence the lower the p-value is, the higher the probability that the relationship is causal rather than random. The standard for p-values is 1.0 – .95 = 0.05 (p ≤ 0.05). A p-value higher than 0.05 is too high to justify a claim of cause.
If no p-value is reported in a study, or the results are not said to be “statistically significant,” then assume the worst: the correlation is not statistically significant. When a statistically significant correlation is present, researchers brag about it. If no p-value is reported, the correlation is evidently nothing to brag about, which the researchers want to hide. But even if a p-value is reported, three cautions are in order about statistics:
- First, statistics make associations sound solid and accurate, but statistical analysis of poor quality data doesn’t make the results any better—i.e., garbage in/garbage out (a problem that plagues many studies of large-scale natural phenomena like climate and weather).
- Second, a statistically significant result does not indicate the magnitude of the effect. There could be a statistically significant reduction in the risk of skin cancer with the use of sunscreen, but if the reduction is only 15% from an already small risk, so what?
- Third, statistics only show that a correlation exists between two things. They don’t show which is the cause and which is the effect. Kellogg’s would have us believe that eating Special K cereal will contribute to weight loss. But it is also possible that women who are already slender, or who are doing other things to lose weight, are drawn to Special K.
- Fourth, statistics suggest the likelihood that some correlation is true, but do not, and cannot, prove it.
6. Properly Planning How to Handle Test Results
How to handle the results of a phase III clinical trial needs to be determined prospectively—before the trial starts—not when results start coming in. How long the trial will last, criteria for including and excluding particular individuals, identifying outliers, the outcome to be measured—all need to be determined at the outset.
If certain participants are excluded during the trial, or discounted as outliers, bias can creep in. The trial needs to be hypothesis-driven, not a fishing expedition looking for any sort of relationship. Researchers may notice interesting, unanticipated correlations during the conduct of a trial, but these need to be tested independently, because this trial was not designed with them in mind. Any claims based on those incidental observations are unjustified by the trial.
7. Distinguishing Low-Dose from High-Dose Effects
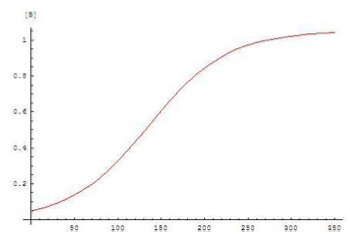 The next caution in evaluating the results of “studies” is to beware conclusions that extrapolate from high-dose to low-dose effects. You know the rationale: even a tiny amount of x is bad for humans because if rats are exposed to megadoses they get sick.The problem with extrapolating from high-dose to low-dose effects is that two relationships between dose and risk are possible. Fearmongers assume a linear relationship, with no safe level—“a single cigarette can kill you,” as a recent Surgeon General said. But equally valid is a sigmoidal (S-shaped) relationship, with high doses conferring significant risk but low doses none. In this case, there is a threshold for exposure below which the dose is safe.
The next caution in evaluating the results of “studies” is to beware conclusions that extrapolate from high-dose to low-dose effects. You know the rationale: even a tiny amount of x is bad for humans because if rats are exposed to megadoses they get sick.The problem with extrapolating from high-dose to low-dose effects is that two relationships between dose and risk are possible. Fearmongers assume a linear relationship, with no safe level—“a single cigarette can kill you,” as a recent Surgeon General said. But equally valid is a sigmoidal (S-shaped) relationship, with high doses conferring significant risk but low doses none. In this case, there is a threshold for exposure below which the dose is safe.
Maybe it’s my Christian faith talking, but I believe God has designed our bodies to be able to deal with small threats. We have a “border patrol” of innate defenses, including macrophages, dendritic cells, and natural killer cells to protect us from small numbers of bacteria and viruses—without our ever knowing we were under attack. All our cells have elaborate DNA repair systems to fix the damage done by low levels of radiation and chemical carcinogens. Our livers are equipped with enzymes, such as cytochrome P-450, to detoxify ingested chemicals. We needn’t worry about exposure to small doses of free radicals or other “oxidants,” because our cells produce anti-oxidants, such as superoxide dismutase, and organelles called peroxisomes.
No doubt high doses of dangerous substances cause disease, but with many substances low doses, as many valid scientific studies seem to show, may not—and in some cases, low doses actually reduce risk by stimulating the body’s designed-in defense mechanisms (a phenomenon called hormesis). In those cases, contrary to the Attorney General’s statement, “a single cigarette can kill you,” maybe a little second-hand smoke now and then could actually prolong your life!
8. Properly Quantifying Risk and Benefit
When the relative risk (or benefit) of something is reported, keep in mind that risk (or benefit) is calculated not by some mathematical formula but by comparing groups. This makes risk and benefit predictions rather “soft.” The smaller the increase in risk (or benefit), the more likely it is due to chance, statistical bias, or confounding (i.e., uncontrolled, uninvestigated) factors such as weight, genes, age, exercise, alcohol use, etc.
Steven Milloy, author of Junk Science Judo, recommends ignoring anything that doesn’t at least double the risk or benefit of a practice, i.e., increase it by at least 100% or decrease it by at least 50%. Smaller changes in risk or benefit are much more likely to be due to mere chance.

9. Of Mice and Men—Distinguishing Species’ Responses to Substances
In discussing the need to distinguish low-dose from high-dose effects, we mentioned the common assumption that if a high dose of a substance causes problems in rats, even a low dose must be dangerous to humans, and we pointed out that with many substances there is a dose threshold below which no risk occurs. An additional problem with extrapolating from animal tests to human use is that humans are not simply big mice. Although both mice and humans are mammals, they obviously have many differences. No animal model can fully reproduce all the features of a human disease. This is one reason why so many drug candidates fail in phase I and phase II clinical trials. In the end, tests must be done with human volunteers.
In sum, a well-designed, well-executed phase III clinical trial is the only proof of cause or cure. But a phase III clinical trial is not possible—for ethical or financial reasons—for all claims. Sometimes we have to settle for second-best, not phase I or phase II clinical trials, but entirely different kinds of studies. Here we shall look at three: cohort studies, case-control studies, and ecologic studies.
Cohort Studies
In a cohort study, researchers recruit a group of healthy people and collect some objective, baseline data about them at the beginning of the study. They are then turned loose to expose themselves to various potential risks and benefits—some will eat broccoli; some will take vitamin supplements; some will drink coffee regularly; some will consume large volumes of alcohol; etc. Researchers ask the members of the cohort to record their exposure to one or lots of things regularly for a period of time, even years. Every so often researchers examine the people or their records and note both the frequency of various diseases and the correlations between risk or benefit factors and the frequency of the disease. The data might suggest, for example, that eating broccoli reduces the risk of colon cancer because those with the lowest incidence of colon cancer consumed more broccoli than those with higher incidence.
At least seven factors make a cohort study less reliable than a phase III clinical trial.
- First, investigators have no control over the level of exposure. Because study participants exposed themselves, the level of exposure is largely unknown—none? high? low? moderate? occasional? frequent? regular? Some members of the cohort will eat broccoli, but exactly how much and how often is not known.
- Second, researchers have little control over the quality of the records kept. Depending on how often they are asked to record their exposures, members might forget some. (Do you remember everything you ate in the past week?)
- Third, by focusing on one variable, e.g., broccoli, investigators might fail to control for all possible confounding variables that could also explain the risk or benefit seen. How can they be sure it was the broccoli and not the amount of aspirin taken?
- Fourth, use of a product does not necessarily mean physiological exposure to it. For example, proper use of an herbicide—according to package directions—minimizes exposure or dangerous contact. Claiming that use of herbicides is linked to breast cancer would be premature.
- Fifth, even if you have been exposed to something, it doesn’t mean you’ve acquired toxic doses of it. Remember the body’s ability to neutralize low doses of various agents. Steven Milloy points out that dioxin—considered by some to be the most toxic man-made substance on earth—is actually created naturally in fried food, fireplaces, and forest fires. It is unavoidable. It makes its way into the food chain and can be found in Ben & Jerry’s “organic” ice cream at levels 2000 times what the EPA declares safe!
- Sixth, cohorts studied might not represent the population as a whole, making extrapolation from a cohort to the public fallacious. One well-known cohort study is the Nurses Health Study, an ongoing study of 90,000 nurses in the Boston area that began in 1976. These nurses are getting old enough to experience various diseases, such as Alzheimer’s and Parkinson’s, which can, presumably, be linked to some earlier exposure. But are these nurses representative of all women? Do they have the same lifestyle, environment, access to medical care, genetic background, etc., as other women?
- Seventh, in a cohort study, there is no placebo group. The groups of “users” and “non-users” are, one hopes, matched for several relevant factors, but it is impossible to match them in every way except for the use of one thing.
In addition, sample sizes still need to be adequate, outcomes need to be measured objectively, and risks or benefits less than 100% must still be recognized as negligible. But cohort studies often fail to meet one or all of these requirements. For example, questionnaires don’t lend themselves to objective measurement of outcomes, such as frequency and intensity of migraines.
For all these reasons, cohort studies are clearly only second-best. A correlation discovered in a cohort study may justify further testing, but not headlines.
Case-Control Studies
Even less reliable than cohort studies, but more common, are case-control studies. Whereas cohort studies are somewhat prospective—i.e., investigators collect baseline data and then periodically measure outcomes—case-control studies are entirely retrospective. In these studies, researchers begin by identifying a group of people who share an illness, e.g., breast cancer, autism, or high blood pressure, as well as a “comparable” group of people without that illness, and then examine their histories to see if all the ill people were exposed to something in common, which presumably caused their illness. Theoretically, the relative risk of exposure to that agent can be calculated by dividing the rate of disease among exposed subjects by the rate of disease among non-exposed subjects.
 Since the investigators in a case-control study begin by looking for individuals with a particular disease, it is relatively easy—probably too easy—to find something they all have in common. For example, nearly everyone with high blood pressure has eaten eggs or high-salt foods. Similarly, nearly every child with autism has received various vaccinations. At this point, the correlation looks air-tight: vaccines ÷ autism = 1 (1 to 1). But it is critical to examine the inverse correlation. What percentage of children who received vaccinations end up with autism? If autism ÷ vaccines = 0.0001 (1 to 10,000), suddenly the correlation doesn’t look so convincing.Most of the time the investigators have an idea what they think causes the disease in question. If they look for a correlation with it, they will probably find it. The problem is, what else do the diseased individuals have in common? All of these confounding variables need to be accounted for, i.e, ruled out as possible causes themselves.
Since the investigators in a case-control study begin by looking for individuals with a particular disease, it is relatively easy—probably too easy—to find something they all have in common. For example, nearly everyone with high blood pressure has eaten eggs or high-salt foods. Similarly, nearly every child with autism has received various vaccinations. At this point, the correlation looks air-tight: vaccines ÷ autism = 1 (1 to 1). But it is critical to examine the inverse correlation. What percentage of children who received vaccinations end up with autism? If autism ÷ vaccines = 0.0001 (1 to 10,000), suddenly the correlation doesn’t look so convincing.Most of the time the investigators have an idea what they think causes the disease in question. If they look for a correlation with it, they will probably find it. The problem is, what else do the diseased individuals have in common? All of these confounding variables need to be accounted for, i.e, ruled out as possible causes themselves.
Since case-control studies are retrospective, they usually rely on data self-reported by people in questionnaires or interviews. They may be asked, for example, “Ever been depressed? Any new allergies? Do you have frequent headaches?” This relies on people’s hazy memory of exposure to countless things during decades of life. In some cases, they are being asked to self-diagnose their ailments, but self-diagnosis is not very reliable. The categories of exposure are also generally rather vague: few, occasional, regular, frequent, seldom. It is really difficult to know who was actually exposed to what, when, and at what doses.
Another problem is that this approach is influenced by the biases of study subjects who already think they know what caused their illness, thanks to premature media reports and hype.
It takes an expert to conduct a rigorous phase III clinical trial. It doesn’t take an expert to do a case-control study, so examining the study author’s credentials is necessary. Does a second grade school teacher have the expertise to design and test an influenza treatment (i.e., Airborne™)? Does someone with an N.D. (naturopathic doctor) degree or a Ph.D. in English? But not many M.D.’s and R.N.’s have expertise in trial design, either, and even they can be found hawking products with dubious claims. Maybe they are not aware of the flaws in the studies done to test their products. Or maybe they are aware, but are taking advantage of a desperate, unsuspecting public to get rich.
Adequate sample size is as important in case-control studies as it is in clinical trials and cohort studies. Andrew Wakefield’s 1998 study claiming MMR vaccine causes autism was based on only 12 children, carefully (not randomly) chosen to obtain the data desired.
Case-control studies share most of the other problems of cohort studies, plus more. But there are “studies” that are even less reliable.
Ecologic Studies
At least with cohort and case-control studies, data are obtained about individuals who can be matched, more or less, with those in a control group. In ecologic studies (not to be confused with biological studies of ecosystems), there are no data on individuals, only on populations.
For example, an ecologic study might compare the incidence of a disease, such as colon cancer, in China and the U.S. It is very possible that the incidence could be quite different. But determining the cause of that difference is very difficult. Most often, people point to the difference in diet between the two countries, assuming that is the cause. But how many other differences exist between the citizens of China and the U.S.?

Or how about the claim that living near power lines causes leukemia, obtained by comparing the incidence of leukemia among people who live near power lines to that of those who do not. How many other differences exist between these two populations? And was the level of radiation given off by those power lines actually objectively measured? Usually not, meaning some less reliable surrogate measurement for exposure had to be used. And remember: exposure ≠ toxicity.
The results of an ecologic study can be summarized in the form of a mathematical equation to form the basis for a computer model, e.g., the number of deaths that would be caused by constructing a new power line over a residential area. But the foundation for this model is inherently weak. The mathematical equations are based on a few of the factors known to influence the outcome, but an unknown number of other relevant factors are unknown. Moreover, the variables may not be constant, but vary themselves over time, making the predictions they are based on even less reliable.
Such models can easily be biased, skewed, or slanted by political correctness, peer pressure (the bandwagon effect—see below), advocacy groups, or economic interests, all of which can influence choices of which variables to focus on and which to ignore. Focusing on the influence of carbon dioxide emissions on global temperature and ignoring or understating the impact of water, solar magnetic wind, cosmic rays, and ocean current cycles is an example.
The findings of an ecologic study may suggest a hypothesis to be tested by a better study, but it should never make a headline or form the basis for governmental policy.
No Study
 All scientific studies are based on some data. But many people base their actions on a single data point: someone said. Someone said eating lettuce will cure arthritis; someone said eating acai berries will cause weight loss; someone said wearing a copper ring or bracelet will improve health. And sometimes they will! But only because of the placebo effect, or by distracting your attention away from the symptom (I could cure any bump or bruise in my children with a popsicle!), or by the natural course of the illness, or by sheer coincidence.If a claim is based on no studies at all, only personal testimonies of efficacy, don’t believe it! The persons giving the testimonies probably received (or only thought they received) a benefit due to the placebo effect, distraction, nature, or sheer coincidence—or because they were paid to give the testimony.
All scientific studies are based on some data. But many people base their actions on a single data point: someone said. Someone said eating lettuce will cure arthritis; someone said eating acai berries will cause weight loss; someone said wearing a copper ring or bracelet will improve health. And sometimes they will! But only because of the placebo effect, or by distracting your attention away from the symptom (I could cure any bump or bruise in my children with a popsicle!), or by the natural course of the illness, or by sheer coincidence.If a claim is based on no studies at all, only personal testimonies of efficacy, don’t believe it! The persons giving the testimonies probably received (or only thought they received) a benefit due to the placebo effect, distraction, nature, or sheer coincidence—or because they were paid to give the testimony.
Dealing with Bias After—and Before—Studies
We have seen how easily bias can influence the conduct and results of a study and what can be done to reduce bias at the study stage. But even if a phase III clinical trial—the gold standard—has met all nine conditions discussed above and yielded valid results, public perception of its significance can be corrupted by bias of other sorts. How can we reduce bias in communicating study results?
Bias in the Popular Media
One arena of post-study bias is the media. By choosing what to report on, the media can bias citizens’ understanding of a topic. News magazines seem to prefer publishing scare stories and mistrust big companies or particular industries—for better or worse reasons.
Journalists could strive against such bias by balancing reporting of good and bad news in terms of its quantified impact—whether harmful or beneficial—and reporting about large and small companies or groups without prejudice based on size. But incentives inherent in the journalistic enterprise make those solutions unlikely.
 Take the focus on bad news. “Bad news is good news; good news is no news,” is a familiar media adage. Why? For one thing, people seem more eager to receive bad news than good news. And why is that? Partly this seems to reflect a fascination with disasters. But partly, too, it simply reflects people’s propensity to focus on anomalies—the unusual—instead of normal things. (Try making a small black mark in the middle of a piece of white paper, showing the paper to people, and asking them what they see. Almost everyone will mention the small black mark; few will mention the vast white space surrounding it.)These two bits of human psychology reinforce each other in generating biased reporting because, surprisingly enough, bad news is far less common than good news. The story about a giant tornado destroying a town gets far more attention than the story of the hundreds of tornadoes every year that hit no towns. The story of one airliner’s crash gets far more attention than the story of thousands of airliners safely completing their journeys every day.
Take the focus on bad news. “Bad news is good news; good news is no news,” is a familiar media adage. Why? For one thing, people seem more eager to receive bad news than good news. And why is that? Partly this seems to reflect a fascination with disasters. But partly, too, it simply reflects people’s propensity to focus on anomalies—the unusual—instead of normal things. (Try making a small black mark in the middle of a piece of white paper, showing the paper to people, and asking them what they see. Almost everyone will mention the small black mark; few will mention the vast white space surrounding it.)These two bits of human psychology reinforce each other in generating biased reporting because, surprisingly enough, bad news is far less common than good news. The story about a giant tornado destroying a town gets far more attention than the story of the hundreds of tornadoes every year that hit no towns. The story of one airliner’s crash gets far more attention than the story of thousands of airliners safely completing their journeys every day.
Since news media rely on advertising income to pay their bills, advertisers respond to audience size, and audiences pay more attention to bad news than good, news editors know they will attract more advertising revenues by conveying bad news than good. Hence the media expose the public to a steady stream of news about bad events, even though good events far outnumber them.
Consumers of popular news media therefore must take it on themselves both to test, so far as they can, how well studies reported meet the criteria discussed above and to look for contrary findings in other studies.
Bias in Scientific Journals
Although many people simply assume that scientists are coolly objective and that science journals are especially so, science journals themselves are another arena of post-study bias, in at least three ways.
First, science journals tend to report only positive results (consistent with the hypothesis being tested), not negative results (inconsistent with the hypothesis), leaving the impression that contradictory results have never been found when, in fact, they have been found but couldn’t get published. This is ironic since no number of positive results can actually prove a theory (Forgetting this is called the “inductive fallacy” or the “fallacy of affirming the consequent.”), while even a single one can disprove it—meaning negative results are in the end at least as important as positive ones, and sometimes more.
Take Wakefield’s article on MMR vaccine and autism, for example. Do most people know that at least 14 studies found no link between vaccines and autism? No. Why not? Because those studies either were never published by science journals (the positive-results bias) or were never picked up by most news media (the bad news or anomaly bias).
There have been calls recently for journals to publish more negative results, because those are just as important as the positive ones, but it is too early to tell how well these calls are being heeded.
Second, peer review, though intended to ensure the quality of scientific publication, doesn’t always work and can actually prevent publication of excellent studies or permit publication of poor ones. Reliable scientific journals subject submitted articles to what one hopes will be rigorous peer review before accepting them for publication. If a study has not passed a peer review process, the results should be viewed with considerable skepticism. This often happens when researchers pitch their results directly to the media, who are always hungry for a big breakthrough or another scare story.
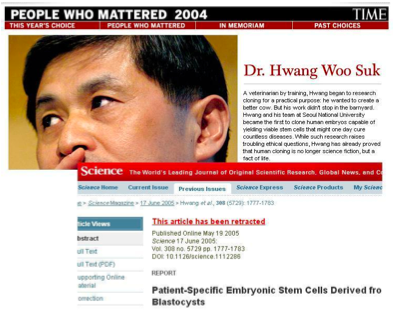
But peer review is no guarantee of credibility if the peer reviewers are as biased or ignorant of proper experimental design as the author of the claim. This can happen with “journals” that specialize in publishing studies on the effects of “naturopathic” remedies. But it can also happen with mainstream science journals, such as Science and Nature. Science, for example, was so anxious to publish the results of embryonic stem cell research that it was duped into publishing fraudulent data in the case of South Korean researcher Woo Suk Hwang. Meanwhile, Science regularly published articles critical of the claims of adult stem cell researchers.
Third, the scientific community, like most other communities, is susceptible to the bandwagon effect: the pressure researchers face to go along with the dominant paradigm—to jump on the bandwagon and play along—rather than espouse an alternative view, lest the bandwagon run them over. This bandwagon effect is enforced by a few dominant personalities in a particular field—some of whom (e.g., Al Gore) may not even be scientists. These dominant personalities can bias the peer review process so that ideas out of tune with the bandwagon’s song never get published—or get published only in obscure journals not followed by the popular media.
Bias in Scientific Funding
A fourth cause of bias occurs before studies get done—affecting which studies do and which don’t. Governments are major funders of scientific research, and they tend to be far more willing to fund studies that are likely to support conventional or “consensus” ideas than those that are likely to challenge them, or that provide rationale for policies already embraced on other grounds. If researchers want to keep their funding and, therefore, their jobs, they have little choice but to jump on the bandwagon.
Many researchers recommend that the problem of government bias in funding be mitigated by adopting a “blue team/red team” approach. For example, in studying anthropogenic climate change, one team could be funded to look for evidence pointing to high influence of human activities on global climate, while another team could be funded to look for evidence pointing to low influence, and their results could then be compared.
 Corporate and private sources, too, fund a lot of research—and ordinarily the world is better for it. But sometimes they bias the outcome. For instance, Wakefield was paid $800,000 to perform his study by a lawyer representing autistic children. Not many researchers can afford to fund their own research, which can be very expensive, so it’s not wrong for researchers to earn a living from their research. But the living must come from the research itself, not its conclusions. If a study author benefits financially not simply from doing the study but from the study’s reaching a particular outcome, be very wary of the results. Personal benefit doesn’t guarantee dishonest or shoddy work, but it does make it more likely.Even so, proper critiques will focus not on “follow the money”—a variety of ad hominem fallacy (attacking the person rather than the argument)—but on the truth or falsehood of premises and the validity or invalidity of study methodology.
Corporate and private sources, too, fund a lot of research—and ordinarily the world is better for it. But sometimes they bias the outcome. For instance, Wakefield was paid $800,000 to perform his study by a lawyer representing autistic children. Not many researchers can afford to fund their own research, which can be very expensive, so it’s not wrong for researchers to earn a living from their research. But the living must come from the research itself, not its conclusions. If a study author benefits financially not simply from doing the study but from the study’s reaching a particular outcome, be very wary of the results. Personal benefit doesn’t guarantee dishonest or shoddy work, but it does make it more likely.Even so, proper critiques will focus not on “follow the money”—a variety of ad hominem fallacy (attacking the person rather than the argument)—but on the truth or falsehood of premises and the validity or invalidity of study methodology.
Conclusion
We are exposed to all kinds of claims, almost daily. How do we know which are credible? We can get a rough idea by determining the type of study that underlies the claim: a phase III clinical trial is better than a cohort study, which is better than a case-control study, which is better than an ecologic study. If possible, run the study through the accompanying Study Validity Checklist to get a more accurate estimate of its credibility.
Nothing substitutes for a reader’s own careful critical reading—following the instruction in 1 Thessalonians 5:21: “Test all things, hold fast what is good.” However, since the articles most of us read do not include details of the design or execution of the supporting studies, it is very difficult for us to ascertain further the credibility of the claims.
For the health field, fortunately, the Cochrane Collaboration has done much of that work. This organization of 31,000 volunteers (note: no financial conflict of interest) investigates all kinds of claims in detail and makes its conclusions available at www.cochrane.org. Two other websites that may be helpful in assessing claims related to health are www.junkscience.com and www.quackwatch.com.
BIBLIOGRAPHY
Beisner, E. C. 2011. If Peer Review Were a Drug, It Wouldn’t Get on the Market. Accessed 2013, July 30.
BESTA—Center for Bioengineering Statistics. 2007. Designing Your Experiment: How Large The Sample Do You Need? Accessed 2013, July 23.
Goldacre, B. 2010. Bad Science—Quacks, Hacks, and Big Pharma Flacks. New York: Faber and Faber.
Landis, S. C., et al. 2012. A call for transparent reporting to optimize the predictive value of preclinical research. Nature 490: 187–191.
Milloy, S. J. 2001. Junk Science Judo—Self-Defense Against Health Scares & Scams. Washington: CATO Institute.
Offit, P. A. 2011. Deadly Choices—How the Anti-Vaccine Movement Threatens Us All. New York: Basic Books.
Vaux, D. L. 2012. Know when your numbers are significant. Nature 192: 180–181.00

